【词库】Python关键词筛选分类,Levenshtein编辑距离算法分词
Python关键词筛选分类,使用Levenshtein模块进行关键词筛选及分类,使用编辑距离的算法,速度相当快。
这个算法有别人用c语言写好的,而且不用分词,因此速度上比上面的算法会快很多,但是分类效果没那么好。一些不相关的词也可能会被分类到同一个分类下。
最终格式为json文件格式!
Levenshtein
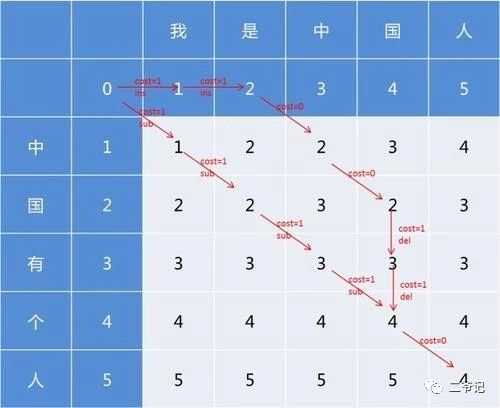
Levenshtein距离,又称编辑距离,指的是两个字符串之间,由一个转换成另一个所需的最少编辑操作次数。许可的编辑操作包括将一个字符替换成另一个字符,插入一个字符,删除一个字符。
例如把 kitten 转换为 sitting:
sitten (k→s)
sittin (e→i)
sitting (→g)
levenshtein() 函数给每个操作(替换、插入和删除)相同的权重。不过,您可以通过设置可选的 insert、replace、delete 参数,来定义每个操作的代价。
百度百科:
https://baike.baidu.com/item/levenshtein/9713212
代码实现:
需要安装Levenshtein模块
安装方法:
pip install python-Levenshtein
关于 Levenshtein 所有函数的用法和注释
#关于 Levenshtein 所有函数的用法和注释
apply_edit() #根据第一个参数editops()给出的操作权重,对第一个字符串基于第二个字符串进行相对于权重的操作
distance() #计算2个字符串之间需要操作的绝对距离
editops() #找到将一个字符串转换成另外一个字符串的所有编辑操作序列
hamming() #计算2个字符串不同字符的个数,这2个字符串长度必须相同
inverse() #用于反转所有的编辑操作序列
jaro() #计算2个字符串的相识度,这个给与相同的字符更高的权重指数
jaro_winkler() #计算2个字符串的相识度,相对于jaro 他给相识的字符串添加了更高的权重指数,所以得出的结果会相对jaro更大(%百分比比更大)
matching_blocks() #找到他们不同的块和相同的块,从第六个开始相同,那么返回截止5-5不相同的1,第8个后面也开始相同所以返回8-8-1,相同后面进行对比不同,最后2个对比相同返回0
median() #找到一个列表中所有字符串中相同的元素,并且将这些元素整合,找到最接近这些元素的值,可以不是字符串中的值。
median_improve() #通过扰动来改进近似的广义中值字符串。
opcodes() #给出所有第一个字符串转换成第二个字符串需要权重的操作和操作详情会给出一个列表,列表的值为元祖,每个元祖中有5个值
#[('delete', 0, 1, 0, 0), ('equal', 1, 3, 0, 2), ('insert', 3, 3, 2, 3), ('replace', 3, 4, 3, 4)]
#第一个值是需要修改的权重,例如第一个元祖是要删除的操作,2和3是第一个字符串需要改变的切片起始位和结束位,例如第一个元祖是删除第一字符串的0-1这个下标的元素
#4和5是第二个字符串需要改变的切片起始位和结束位,例如第一个元祖是删除第一字符串的0-0这个下标的元素,所以第二个不需要删除
quickmedian() #最快的速度找到最相近元素出现最多从新匹配出的一个新的字符串
ratio() #计算2个字符串的相似度,它是基于最小编辑距离
seqratio() #计算两个字符串序列的相似率。
setmedian() #找到一个字符串集的中位数(作为序列传递)。 取最接近的一个字符串进行传递,这个字符串必须是最接近所有字符串,并且返回的字符串始终是序列中的字符串之一。
setratio() #计算两个字符串集的相似率(作为序列传递)。
subtract_edit() #从序列中减去一个编辑子序列。看例子这个比较主要的还是可以将第一个源字符串进行改变,并且是基于第二个字符串的改变,最终目的是改变成和第二个字符串更相似甚至一样
参考案例:
Python文本相似性计算之编辑距离详解
https://www.jb51.net/article/98449.htm
几个关键点:
1.Levenshtein 库的安装
安装方法:
pip install python-Levenshtein
你可能也会碰到这样的报错:
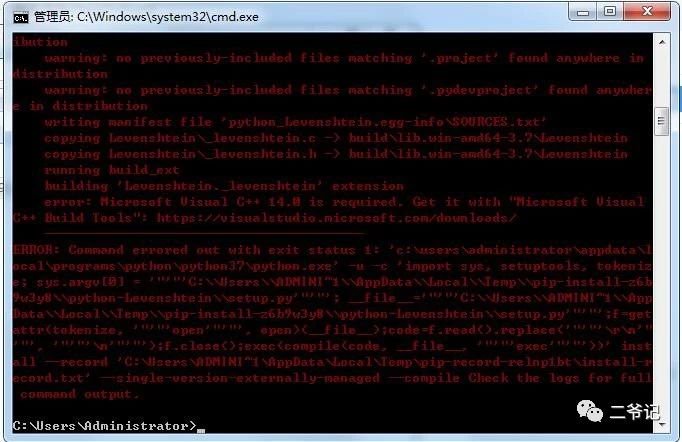
解决方案:
Python的一大亮点就是对于我们在学习中遇到的常见问题,它都有很多现成的module可供使用,但是,在我们安装这些module时,可能会出现**“error: Microsoft Visual C++ 14.0 is required. Get it with “Microsoft Visual C++ Build Tools”**这样的错误。
对于此类问题,提供以下两种解决方案:
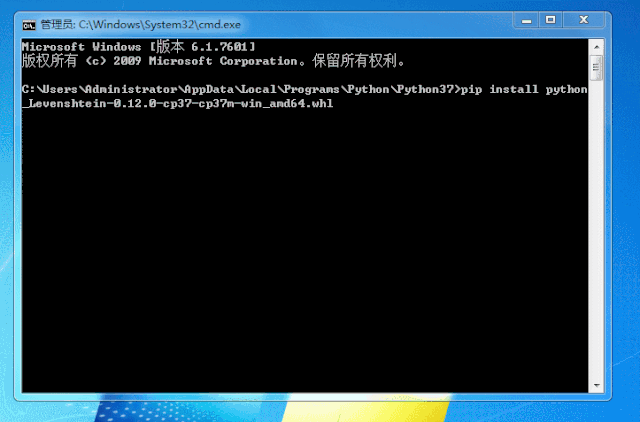
方法一:下载所需模块的.whl文件,然后再以pip的形式安装:
1)常用模块的.whl文件的下载地址:Unofficial Windows Binaries for Python Extension Packages
2)以模块Twisted为例,我们再下载了该模块的.whl文件后,在控制台通过命令安装
方法二:
最根本的解决办法:按照错误提示,需要安装Microsoft Visual C++ 14.0才能解决问题,那我们安装一下应该就没问题了:
Microsoft Visual C++ 14.0
百度云下载地址为:
https://pan.baidu.com/s/12TcFkZ6KFLhofCT-osJOSg
提取码:wkgv
这里我采用了第一种方法:
本地安装whl文件python
1、下载whl离线文件到本地,放到c盘根目录(任意位置均可,只是方便安装)
https://pypi.org/
https://www.lfd.uci.edu/~gohlke/pythonlibs/
(推荐用这个地址下载whl文件,国内源,速度快。ctrl+f找到自己需要的文件)
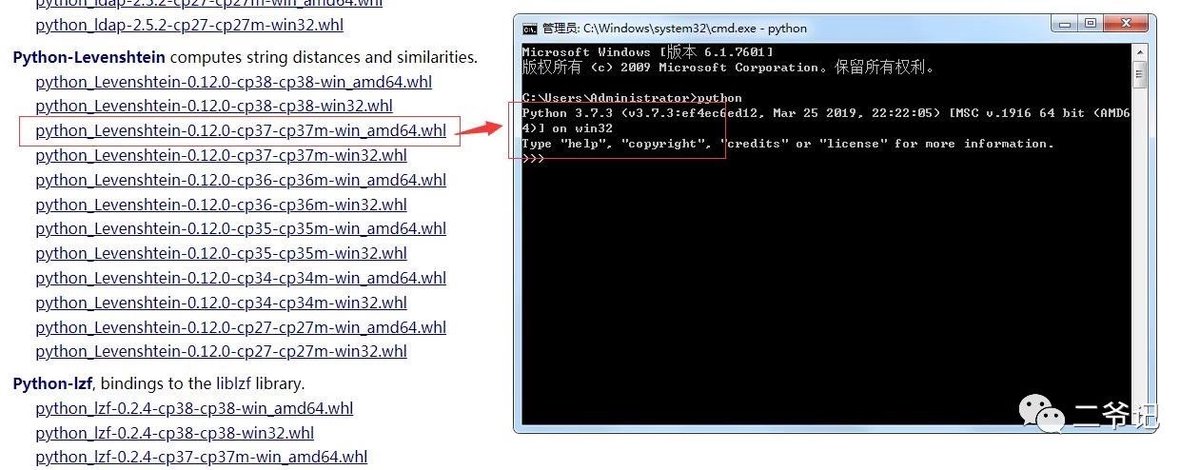
2、 cmd到存放whl文件的目录
3、pip安装whl离线文件
pip install ****.whl
(****.whl是我们下载的whl的文件名称)
2.json.dumps()用于将字典形式的数据转化为字符串,json.loads()用于将字符串形式的数据转化为字典
3.json 中的ensure_ascii=False
json.dumps 序列化时对中文默认使用的ascii编码.想输出真正的中文需要指定ensure_ascii=False。
>>> import json
>>> print json.dumps('中国')
"\u4e2d\u56fd"
>>> import json
>>> print json.dumps('中国')
"\u4e2d\u56fd"
>>> print json.dumps('中国',ensure_ascii=False)
"中国"
>>>运行效果:
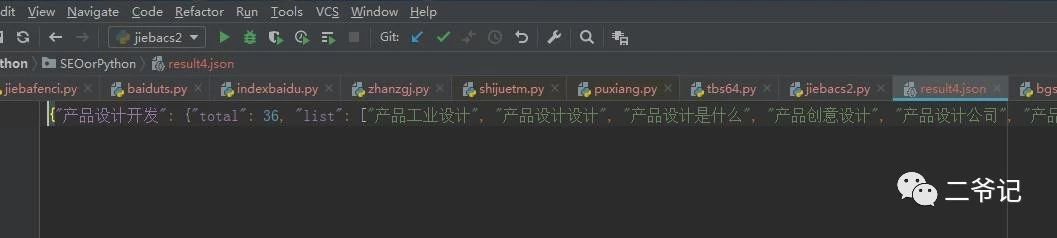
分词效果:

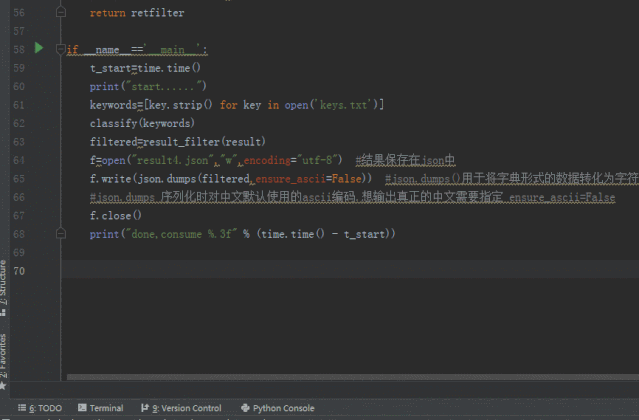
附完整代码:
#分词方法,使用Levenshtein模块分类
# -*- coding: utf-8 -*-
import json
import time
import Levenshtein #导入 Levenshtein 模块
result={}
def classify(keyword_list):
"""
使用while循环的方法计算和分类
:param keyword_list: 要分类的关键词队列
:return: None
"""
muci=keyword_list.pop(0) #取第一个词
result[muci]={"total":0,"list":[]}
last=keyword_list[-1] #最后一个词
total_classify=0
remain=len(keyword_list)
while keyword_list:
kw=keyword_list.pop(0) #提取列表中的笑一个词
simi=Levenshtein.jaro_winkler(kw,muci)
if simi >= 0.8:
result[muci]["list"].append(kw)
result[muci]["total"] += 1
remain -= 1
else:
keyword_list.append(kw)
if kw == last and keyword_list: #如果已经是最后一个了
total_classify += 1
print("Has been classified %d , remain %d" % (total_classify, remain))
muci=keyword_list.pop(0)
remain -= 1
result[muci]={"total":0,"list":[]}
if keyword_list:
last=keyword_list[-1]
else:
break
def result_filter(result_dict,bigthan=10):
"""
结果滤筛选函数
由于使用该方法会得到很多分类,有些分类是没有关键词的或者只有少数相关词
那么对于这些分类就可能不需要了,那么我们就直接把它们过滤掉就好了
:param result_dict: 要筛选的分类结果
:param bigthan: 相关词数量大于或者等于该数的分类将保存
:return: 过滤后的结果
"""
retfilter={}
for item,values in result_dict.items():
if values["total"] >bigthan:
retfilter[item]=values
return retfilter
if __name__=='__main__':
t_start=time.time()
print("start......")
keywords=[key.strip() for key in open('keywords.txt',encoding='utf-8')]
classify(keywords)
filtered=result_filter(result)
f=open("result4.json","w",encoding="utf-8") #结果保存在json中
f.write(json.dumps(filtered,ensure_ascii=False)) #json.dumps()用于将字典形式的数据转化为字符串,json.loads()用于将字符串形式的数据转化为字典
#json.dumps 序列化时对中文默认使用的ascii编码.想输出真正的中文需要指定 ensure_ascii=False
f.close()
print("done,consume %.3f" % (time.time() - t_start))注意keywords.txt格式为utf-8!
尝试了一下分词的速度还是非常快速的!
相关阅读:
结巴分词seo应用,Python jieba库基本用法及案例参考